
06505 Big Data Analytics in Produktion und Instandhaltung
|
Wissen stellt eine wichtige Unternehmensressource dar, deren effiziente Nutzung zur Entscheidungs- und Planungsunterstützung für den Unternehmenserfolg insgesamt von großer Bedeutung ist. Moderne Informationstechnologien ermöglichen eine strukturierte digitale Speicherung großer, inhomogener und mit hoher Geschwindigkeit entstehender Datenmengen (sog. Big Data), ihre effiziente Analyse (sog. Big Data Analytics) in der Produktion und Instandhaltung wird jedoch seltener fokussiert. Im Beitrag wird ein systematisches Vorgehen zur Realisierung von Big-Data-Analytics-Projekten und somit zur Wissensentdeckung im produktionsnahen Umfeld dargestellt und anhand von Anwendungsbeispielen aus dem Bereich der Qualitätsüberwachung in der laufenden Produktion und der prädiktiven Instandhaltung erläutert. von: |
1 Einleitung
Wachsender Datenbestand
In Produktionsunternehmen nimmt der Bestand an produktionstechnischen Daten durch den vermehrten Einsatz digitaler Planungs-, Informations- und Steuerungswerkzeuge permanent zu. Diese Entwicklung wird durch die Einführung cyber-physischer Systeme (CPS) im Kontext der vierten industriellen Revolution (sog. Industrie 4.0) weiter beschleunigt [1]. Aktuelle Schätzungen zeigen, dass ungefähr 90 % aller Produktionsprozesse durch Informations- und Kommunikationstechnologien unterstützt werden [2]. Somit tragen diese maßgeblich zur Entstehung von Big Data bei, die durch eine hohe Vielfalt (bzw. Inhomogenität), Entstehungsgeschwindigkeit und Gesamtmenge der Datenbestände (Variety, Velocity und Volume) charakterisiert sind [3]. Die Anwendung von prädiktiven Analyseverfahren (predictive analytics) aus den Bereichen Data Mining, Statistik oder Künstliche Intelligenz auf diese Daten wird unter dem Begriff Big Data Analytics zusammengefasst [3]. Es ist von entscheidender Bedeutung, produktionsnahe Daten im Rahmen von Big-Data-Analytics-Ansätzen auszuwerten und das darin verborgene Wissen zu nutzen, um Kostensenkungen zu bewirken und Wettbewerbsvorteile zu generieren.
In Produktionsunternehmen nimmt der Bestand an produktionstechnischen Daten durch den vermehrten Einsatz digitaler Planungs-, Informations- und Steuerungswerkzeuge permanent zu. Diese Entwicklung wird durch die Einführung cyber-physischer Systeme (CPS) im Kontext der vierten industriellen Revolution (sog. Industrie 4.0) weiter beschleunigt [1]. Aktuelle Schätzungen zeigen, dass ungefähr 90 % aller Produktionsprozesse durch Informations- und Kommunikationstechnologien unterstützt werden [2]. Somit tragen diese maßgeblich zur Entstehung von Big Data bei, die durch eine hohe Vielfalt (bzw. Inhomogenität), Entstehungsgeschwindigkeit und Gesamtmenge der Datenbestände (Variety, Velocity und Volume) charakterisiert sind [3]. Die Anwendung von prädiktiven Analyseverfahren (predictive analytics) aus den Bereichen Data Mining, Statistik oder Künstliche Intelligenz auf diese Daten wird unter dem Begriff Big Data Analytics zusammengefasst [3]. Es ist von entscheidender Bedeutung, produktionsnahe Daten im Rahmen von Big-Data-Analytics-Ansätzen auszuwerten und das darin verborgene Wissen zu nutzen, um Kostensenkungen zu bewirken und Wettbewerbsvorteile zu generieren.
Data Mining
Bei der Durchführung von Big-Data-Analytics-Projekten werden meist Data-Mining-Verfahren eingesetzt. Data Mining bezeichnet die Anwendung spezieller Algorithmen, um unbekannte und nicht triviale Strukturen, Zusammenhänge und Trends in großen Datenmengen zu entdecken [4]. Der Einsatz von Data Mining im produktionsnahen Umfeld hat seinen Ursprung in den 1990er-Jahren, bspw. Teilefamilienbildung [5], und erlangt im Rahmen von Forschungsansätzen zu Big Data Analytics aktuell einen stetig wachsenden Verbreitungsgrad. In diesem Zusammenhang wird Data Mining für eine Vielzahl verschiedener Anwendungszwecke wie der Qualitätssicherung, der Fertigungssteuerung, der Fehlererkennung und der prädiktiven Instandhaltung eingesetzt [6]. Hierbei müssen insbesondere die Anforderungen produktionsnaher Datenbestände berücksichtigt und die Akzeptanz von Big Data Analytics bei den Entscheidungsträgern gefördert werden. Daher wird im Beitrag ein systematisches Prozessmodell zur Wissensentdeckung in industriellen Datenbeständen (Knowledge Discovery in Industrial Databases, KDID) und somit zur Durchführung von Big-Data-Analytics-Projekten vorgestellt sowie anhand von Projektbeispielen aus der Praxis erläutert.
Bei der Durchführung von Big-Data-Analytics-Projekten werden meist Data-Mining-Verfahren eingesetzt. Data Mining bezeichnet die Anwendung spezieller Algorithmen, um unbekannte und nicht triviale Strukturen, Zusammenhänge und Trends in großen Datenmengen zu entdecken [4]. Der Einsatz von Data Mining im produktionsnahen Umfeld hat seinen Ursprung in den 1990er-Jahren, bspw. Teilefamilienbildung [5], und erlangt im Rahmen von Forschungsansätzen zu Big Data Analytics aktuell einen stetig wachsenden Verbreitungsgrad. In diesem Zusammenhang wird Data Mining für eine Vielzahl verschiedener Anwendungszwecke wie der Qualitätssicherung, der Fertigungssteuerung, der Fehlererkennung und der prädiktiven Instandhaltung eingesetzt [6]. Hierbei müssen insbesondere die Anforderungen produktionsnaher Datenbestände berücksichtigt und die Akzeptanz von Big Data Analytics bei den Entscheidungsträgern gefördert werden. Daher wird im Beitrag ein systematisches Prozessmodell zur Wissensentdeckung in industriellen Datenbeständen (Knowledge Discovery in Industrial Databases, KDID) und somit zur Durchführung von Big-Data-Analytics-Projekten vorgestellt sowie anhand von Projektbeispielen aus der Praxis erläutert.
2 KDD-Prozessmodelle zur Wissensentdeckung
Zur Wissensentdeckung in Datenbeständen (Knowledge Discovery in Databases, KDD) wurde in Wissenschaft und Praxis eine Vielzahl von Prozessmodellen entwickelt [1], die einen systematischen und strukturierten Projektablauf sicherstellen sollen (s. Abb. 1).
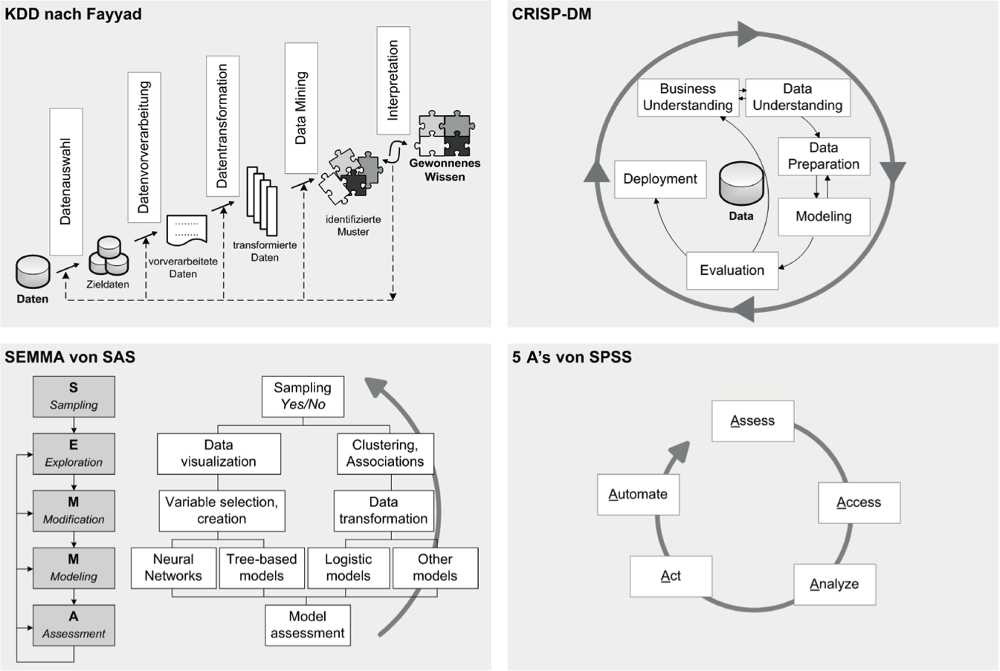
2.1 Anbieterneutrale KDD-Prozessmodelle
Selektion und Vorbereitung der Daten im KDD
Eines der ersten und in der wissenschaftlichen Literatur bis heute am weitesten verbreiteten KDD-Prozessmodelle wurde Mitte der 1990er-Jahre von Fayyad, Piatetsky-Shapiro und Smyth entwickelt [8]. Das Modell besteht aus insgesamt fünf Phasen (Datenauswahl, Datenvorverarbeitung, Datentransformation, Data Mining, Ergebnisinterpretation), die schrittweise durchlaufen werden und Korrekturen bzw. Anpassungen der Entscheidungen vorangegangener Phasen zulassen. Im Rahmen der Datenauswahl werden die für die Untersuchung relevanten Daten aus dem Inputdatenbestand selektiert. Diese werden in der darauffolgenden Phase auf die eigentliche Datenanalyse vorbereitet, indem sie auf ihre Qualität untersucht und Datenmängel eliminiert werden. Dazu werden sowohl fehlende als auch fehlerhafte Werte korrigiert bzw. eliminiert [8].
Eines der ersten und in der wissenschaftlichen Literatur bis heute am weitesten verbreiteten KDD-Prozessmodelle wurde Mitte der 1990er-Jahre von Fayyad, Piatetsky-Shapiro und Smyth entwickelt [8]. Das Modell besteht aus insgesamt fünf Phasen (Datenauswahl, Datenvorverarbeitung, Datentransformation, Data Mining, Ergebnisinterpretation), die schrittweise durchlaufen werden und Korrekturen bzw. Anpassungen der Entscheidungen vorangegangener Phasen zulassen. Im Rahmen der Datenauswahl werden die für die Untersuchung relevanten Daten aus dem Inputdatenbestand selektiert. Diese werden in der darauffolgenden Phase auf die eigentliche Datenanalyse vorbereitet, indem sie auf ihre Qualität untersucht und Datenmängel eliminiert werden. Dazu werden sowohl fehlende als auch fehlerhafte Werte korrigiert bzw. eliminiert [8].
Analyse, Interpretation und Auswertung der Daten im KDD
Im Rahmen der Datentransformation werden die Daten in eine für die Anwendung des gewählten Data-Mining-Verfahrens erforderliche Form gebracht. In diesem Zusammenhang ist unter anderem das für die Anwendung des Data-Mining-Verfahrens erforderliche Skalenniveau der Daten zu definieren. So kann bspw. zur Anwendung einiger Clusterbildungsverfahren eine Normalisierung numerischer Werte oder eine Transformation der Merkmale in ein dichotomes Skalenniveau erforderlich sein. Die vorverarbeiteten und transformierten Daten werden anschließend mit dem gewählten Data-Mining-Verfahren (bspw. Regressionsanalyse, Klassifikationsverfahren, Clustering) analysiert, um bisher unbekannte Muster und Zusammenhänge zu identifizieren und somit das eigentliche Ziel der Wissensentdeckung zu erreichen. In der abschließenden Phase werden die gefundenen Muster interpretiert und ausgewertet, sodass mit den gewonnenen Erkenntnissen neues Wissen generiert und genutzt werden kann [8]. Das von Fayyad et al. entwickelte KDD-Prozessmodell erfordert insgesamt einen umfassenden Datenbestand und sieht keine Integration von anwendungsfeldspezifischem Expertenwissen in den Analyseprozess vor. Dies stellt jedoch eine unabdingbare Grundlage für die erfolgreiche Realisierung von Big-Data-Analytics-Projekten in der betrieblichen Praxis dar.
Im Rahmen der Datentransformation werden die Daten in eine für die Anwendung des gewählten Data-Mining-Verfahrens erforderliche Form gebracht. In diesem Zusammenhang ist unter anderem das für die Anwendung des Data-Mining-Verfahrens erforderliche Skalenniveau der Daten zu definieren. So kann bspw. zur Anwendung einiger Clusterbildungsverfahren eine Normalisierung numerischer Werte oder eine Transformation der Merkmale in ein dichotomes Skalenniveau erforderlich sein. Die vorverarbeiteten und transformierten Daten werden anschließend mit dem gewählten Data-Mining-Verfahren (bspw. Regressionsanalyse, Klassifikationsverfahren, Clustering) analysiert, um bisher unbekannte Muster und Zusammenhänge zu identifizieren und somit das eigentliche Ziel der Wissensentdeckung zu erreichen. In der abschließenden Phase werden die gefundenen Muster interpretiert und ausgewertet, sodass mit den gewonnenen Erkenntnissen neues Wissen generiert und genutzt werden kann [8]. Das von Fayyad et al. entwickelte KDD-Prozessmodell erfordert insgesamt einen umfassenden Datenbestand und sieht keine Integration von anwendungsfeldspezifischem Expertenwissen in den Analyseprozess vor. Dies stellt jedoch eine unabdingbare Grundlage für die erfolgreiche Realisierung von Big-Data-Analytics-Projekten in der betrieblichen Praxis dar.
CRISP-DM-Modell
Im Gegensatz zu diesem eher wissenschaftlich geprägten KDD-Modell wurde Ende der 1990er-Jahre von einem Unternehmenskonsortium das Cross Industry Standard Process for Data Mining (CRISP- DM) entwickelt, das auf den Erfahrungen aus praktischen Projekten beruht und sich mittlerweile als der industrielle Standard für KDD durchgesetzt hat [7]. Das CRISP-DM-Prozessmodell setzt sich aus sechs iterativen Phasen (Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment) zusammen. Im Vergleich zum KDD-Modell von Fayyad, Piatetsky-Shapiro und Smyth [7], [12], [4] repräsentiert CRISP- DM die praxisbezogene Sicht auf Data-Mining-Projekte [12]. Das wird insbesondere durch den Einbezug von Prozess- und Datenverständnis sowie von Expertenwissen aus dem Anwendungsbereich gewährleistet [4].
Im Gegensatz zu diesem eher wissenschaftlich geprägten KDD-Modell wurde Ende der 1990er-Jahre von einem Unternehmenskonsortium das Cross Industry Standard Process for Data Mining (CRISP- DM) entwickelt, das auf den Erfahrungen aus praktischen Projekten beruht und sich mittlerweile als der industrielle Standard für KDD durchgesetzt hat [7]. Das CRISP-DM-Prozessmodell setzt sich aus sechs iterativen Phasen (Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, Deployment) zusammen. Im Vergleich zum KDD-Modell von Fayyad, Piatetsky-Shapiro und Smyth [7], [12], [4] repräsentiert CRISP- DM die praxisbezogene Sicht auf Data-Mining-Projekte [12]. Das wird insbesondere durch den Einbezug von Prozess- und Datenverständnis sowie von Expertenwissen aus dem Anwendungsbereich gewährleistet [4].
2.2 Anbieterspezifische KDD-Prozessmodelle
Neben den oben vorgestellten anbieterneutralen KDD-Prozessmodellen existieren weitere im wissenschaftlichen und praktischen Umfeld speziell von den Anbietern von Data- Mining-IT-Lösungen entwickelte Modelle [11]. Zwei bekannte Beispiele dafür sind das SEMMA-Modell (Sample, Explore, Modify, Model, Assess) von SAS [9] sowie das 5A-Modell (Assess, Access, Analyze, Act, Automate) von SPSS [11]. Diese unterstützen eine eher statistisch geprägte Sichtweise auf Data Mining, ohne die Herausforderungen von Big-Data-Analytics-Projekten zu berücksichtigen.
